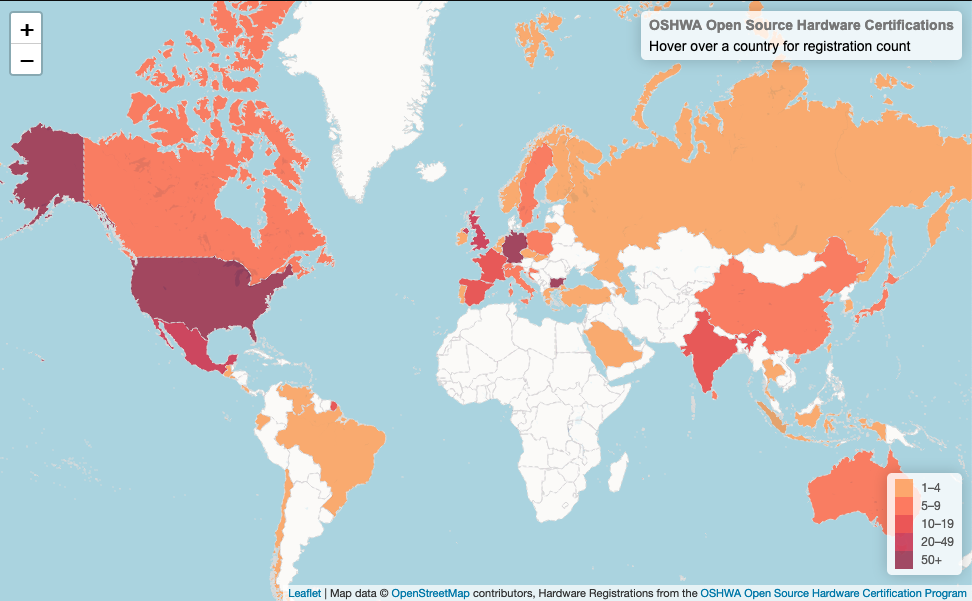
Update 2/11/24: The original version of this map didn't fully work because the OSHWA api paginates the results it provides. The original version did not take that into account, so only displayed the first 100 certifications. The newly updated version downloads all of the entries before creating the map, so it is actually complete. It also includes a count of the total entries and number of countries with certifications in the header. The new code still more or less works the same way, although there is now an initial step to loop through the api until everything is downloaded. You can find the updated version in the repo referenced below. Also, the API key expires every 100 days, so if you are reading this more than 100 days from 2/11/24 and the map is not loading, that may be the problem. There are instructions for getting your own API key in the repo.
Read More...