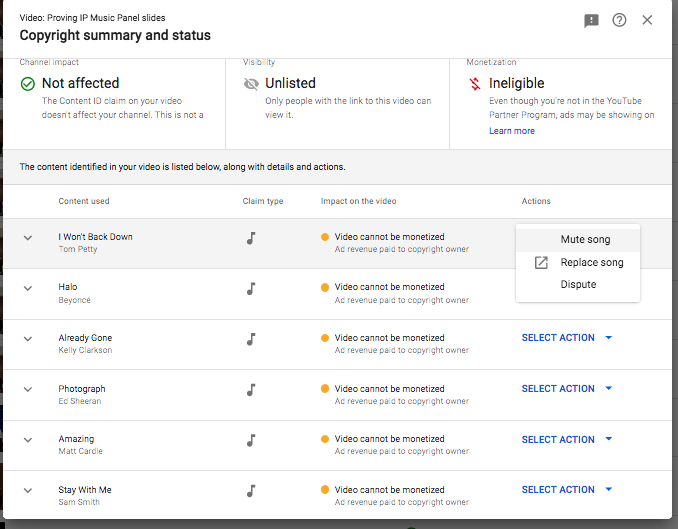
In celebration of Public Domain Day 2020 I decided to try to turn the old monitor in my office into a picture frame to display a rotating collection of public domain works. The Cleveland Museum of Art (CMA) launched a robust Open Access program in 2019, so I decided to use their API to power it. This blog post explains all of the steps in creating the project so you can make one too.
This is a fairly lightweight project, so all you need to make it happen is:
- A monitor
- A raspberry pi (or any other computer)
- Some code
Most of this post is about the code. The theory behind this project is that there is a website that regularly pulls a new image from the CMA’s API and displays it along with some information like the work’s title and creator. The raspberry pi boots into a fullscreen browser displaying that page. The screen also needs to automatically turn off at night because it is a waste to keep the monitor on all night when there is no one around to see it.
The entire project is a double celebration of openness. In addition to the works being displayed, the only reason I could even begin to build it is that the open nature of the internet’s architecture allows me to peek at better-designed sites to learn from them. Open educational resources like the Coding Train have taught me just enough javascript to be able to put something like this together.
The Site
I decided (guessed?) that the easiest way to make all of this work was to create a website that displayed the rotating set of pictures. I’m bad at javascript, so this gave me a chance to learn a little bit more about it.
The self-contained site is available in this repo. If you don’t care about how it works, you can just access a live version of it here.
index.html
This file is minimal and straightforward - it is essentially just a container with pointers to a stylesheet and the script. The one thing to note is that the script is inside of a container div:
<div class='container'>
<script src='script.js'></script>
</div>
This allows me to overlay the text descriptions on top of the image.
script.js
This file is the heart of the action. I will walk through each section to explain what it does. All of the console.log lines are just for my own troubleshooting and can basically be ignored.
//function to generate a random number
function getRndInteger(min, max) {
return Math.floor(Math.random() * (max - min) ) + min;
}
This initial function is used to generate a random number. The random number is needed in two places: first to pick the image from the collection, and second to determine how long the image will stay up before the page refreshes.
//uses the function to pick a random image in the collection
var offset = getRndInteger(1, 31278);
//inserts that random number into the request url, returning a json file
var target_json_url = "https://openaccess-api.clevelandart.org/api/artworks/?limit=10&indent=1&cc0=1&has_image=1&skip=" + offset;
This block of code is used to access the entry via the CMA’s API. I believe that there are 31,277 entries in the CMA’s open access catalog that have an image. The first line picks a random number between 1 and 31,277. The second line uses the API’s syntax to jump to the work that corresponds to that number.
The limit=10&indent=1 elements in the URL are probably unnecessary. The cc0=1&has_image=1 elements are important - they limit results to ones that have a CC0 license and have an image associated with the entry. Those are the open access entries that I care about.
//create new request object instance
let request = new XMLHttpRequest();
//opens the file
request.open('GET', target_json_url);
request.responseType = 'json'
request.send();
This block of text creates an object to hold the json file that the API returns at the URL and then opens the json file into it. Basically it creates and fills the container for the JSON file that corresponds to the object that we randomly selected above.
request.onload = function() {
const response_json = request.response;
//gets the image URL + tombstone of a random image from the collection and turns it into an array assigned to a variable
var found_image_info = grabImageInfo(response_json);
var picked_image_URL = found_image_info[0];
var picked_image_tombstone = found_image_info[1];
var picked_image_title = found_image_info[2];
var picked_image_author = found_image_info[3];
var picked_image_date = found_image_info[4];
//creates the image to be posted
var img = document.createElement("img");
img.src = picked_image_URL;
img.alt = 'picked_image_tombstone';
//creates the text
var tomb_text = document.createTextNode(picked_image_tombstone)
//creates the linebreak
var linebreak = document.createElement('br');
let item = document.createElement('div');
item.classList.add('item');
item.innerHTML = `<div class="container"><img class="beach-image" src="${picked_image_URL}" alt="beach image"/><div class="textStyle">${picked_image_title}<br>${picked_image_author}<br>${picked_image_date}</div></div>`;
document.body.appendChild(item);
//set up the refresh
//time is in ms
//this sets the range
var refresh_interval = getRndInteger(5000, 20000)
console.log("refresh rate = " + refresh_interval);
//this uses the range to reset the page
setTimeout(function(){
location = ''
},refresh_interval)
}
This block is where most of the work happens, so I’ll break it down in smaller pieces. The reason it is all tucked into a request.onload function is that the code in this block waits to load until it has successfully loaded the data from the API in the background.
const response_json = request.response;
//gets the image URL + tombstone of a random image from the collection and turns it into an array assigned to a variable
var found_image_info = grabImageInfo(response_json);
This first section assigns the contents of the JSON file to a variable and then sends the JSON file to the grabimageInfo function described below. That function pulls all of the data I care about out of the JSON file and puts it in an array that can be accessed with bracket notation (see next block).
var picked_image_URL = found_image_info[0];
var picked_image_tombstone = found_image_info[1];
var picked_image_title = found_image_info[2];
var picked_image_author = found_image_info[3];
var picked_image_date = found_image_info[4];
This section assigns a variable to each element in the found_image_info array.
//creates the image to be posted
var img = document.createElement("img");
img.src = picked_image_URL;
img.alt = 'picked_image_tombstone';
This section creates an image element. The source is the URL that comes from the JSON file and the alt text is the tombstone text from the JSON file.
let item = document.createElement('div');
item.classList.add('item');
item.innerHTML = `<div class="container"><img class="beach-image" src="${picked_image_URL}" alt="beach image"/><div class="textStyle">${picked_image_title}<br>${picked_image_author}<br>${picked_image_date}</div></div>`;
document.body.appendChild(item);
This section creates the HTML to be added to the index.html file. The item.innerHTML section creates an HTML payload with the image and the title, author, and date overlayed on top of it. If you want to change what is displayed over the image this is where you should start messing around.
//set up the refresh
//time is in ms
//this sets the range
var refresh_interval = getRndInteger(5000, 20000)
console.log("refresh rate = " + refresh_interval);
//this uses the range to reset the page
setTimeout(function(){
location = ''
},refresh_interval)
This is the section that sets up the page refresh. The arguments you pass to the getRndInteger variable determines the bounds of the refresh rate. Remember that the numbers are in ms. I decided to make this slightly random instead of a fixed number to add a bit of variability to the display.
function grabImageInfo(jsonObj) {
//pulls the elements of each piece and assigns it to a variable
var data_url = jsonObj['data'][0]['images']['web']['url']
var data_tombstone = jsonObj['data'][0]['tombstone']
console.log(data_tombstone)
var data_title = jsonObj['data'][0]['title']
//the author info sometimes doesn't exist, which screws up the function. Pulling this part out of the function fixes it because the jsonObj is not evaluated before the try/catch. I am not sure what that means but it works.
try {
data_author = jsonObj['data'][0]['creators'][0]['description']
}
catch (e) {
data_author = ''
}
var data_creation_date = jsonObj['data'][0]['creation_date']
console.log("url = " +data_url)
//creates an array with the URL, tombstone, title, author, and creation date of the random object picked
var function_image_data = [data_url, data_tombstone, data_title, data_author, data_creation_date]
//returns that array
return function_image_data;
}
This is the function to extract data from the JSON file. It pulls each relevant element and then adds it to an array. Each of the var data_url = jsonObj['data'][0]['images']['web']['url'] requests are essentially the same, with the difference being where in the JSON file they are looking for the relevant data.
try {
data_author = jsonObj['data'][0]['creators'][0]['description']
}
catch (e) {
data_author = ''
}
The author variable works slightly differently. Sometimes the author data does not exist in the records. This structure allows the script to handle errors without crashing.
var function_image_data = [data_url, data_tombstone, data_title, data_author, data_creation_date]
//returns that array
return function_image_data;
Finally, each element of the data is put into an array and returned out of the function. The order of how the data is added to the array is arbitrary, but it is consistent so if you move something around here make sure to change how you pull them out at the top of the script.
style.css
This is also a fairly strightforward css file. The .textStyle section is what you use to style the text. I also believe that the .container section needs to be set to relative in order for the overlay to work.
The most interesting part of the file is probably the @font-face section. That loads the custom font. The font is the fantastic font that the Cooper Hewitt made available as part of their open access project a few years ago. I always like using the font for open access-related projects. The fonts live in the /data folder. They are applied to all of the text in the * section.
The Pi
Once you have everything up and running you can access it from any browser. You can try it here, press F11, and just let it happen in full screen.
If you want to run it constantly as a picture frame it makes sense to devote a computer to the task. A Raspberry Pi is a prefect candidate because it is inexpensive and draws a relatively small amount of electricity.
You could set things up so the pi hosts the file locally and then just opens it. I decided not to do that, mostly because that would involve automatically starting a local server on the pi, which was one more thing to set up. Since the service needs to be online to hit the API anyway, I thought it would be easier to just set up the page on my own domain. I have no idea if that is actually easier.
There are two and a half things you need to do in order to set the pi to automatically boot into displaying the site in fullscreen mode as a full time appliance.
Start in Fullscreen Mode
You can start Chromium in fullscreen mode from the command line. That means you can add the line to the pi’s autostart file. Assuming your username is just ‘pi’ (the default when you start raspbian), open a terminal window and type:
nano /home/pi/.config/lxsession/LXDE-pi/autostart
This will allow you to edit the autostart file directly. Add this line to the file (which is probably otherwise blank):
@chromium-browser --start-fullscreen michaelweinberg.org/cma_pd
You can change the final URL to whatever you like. If you are hosting your own version of this page, that is where to make the switch.
You may find that your fullscreen display still gets a scroll bar on one side. If that’s the case, the half thing you need to do is open chromium and type chrome://flags in the toolbar. Once you are looking at the flags, search for overlay scrollbars and enable it. That will hide the scroll bars.
Turn off the Screen
The final thing you might want to do is turn off the screen of the display at night. In order to do this you need to make two entries in cron. Here is a nice intro to cron. Cron is a linux utility that allows you to schedule commands.
The commands you end up scheduling may vary based on your particular setup. This is a helpful tutorial laying out options to make this happen. The ones that worked for me were the vcgencmd ones.
In order to schedule those I opened a terminal window and typed crontab -e. I then added two lines. This line turned off the display: vcgencmd display_power 0 and this line turned it back on: vcgencmd display_power 1. Use crontab to schedule these at appropriate times.
That’s that. This will let you set up a rotating set of public domain images on any display you might have access to. Good luck with your own version.
List image: The Biglin Brothers Turning the Stake, Thomas Eakins, 1873